DBeaver Community | Free Universal Database Tool
DBeaver Universal Database Tool DBeaver Community is a free cross-platform database tool for developers, database administrators, analysts, and everyone working with data. It supports all popular SQL databases like MySQL, MariaDB, PostgreSQL, SQLite, Apach
dbeaver.io
DBeaver 에서, 데이터 추출 시 한글 깨짐 현상과 해결 방법 정리합니다.
(현상)
DBeaver 에서 조회 결과를 데이터 추출 후,
메모장이나, 탐색기 미리보기 에서는 한글이 정상적으로 보입니다
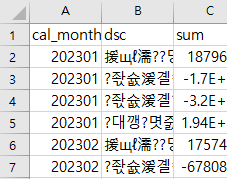
하지만, 엑셀에서 열면 아래와 같이 한글 깨짐 현상이 생합니다
구글링 하면, 아주 간단하게(?) 문제 해결 방법이 나오긴 하지만
그 원인과 해결방법을 좀더 정리해 봅니다
(원인)
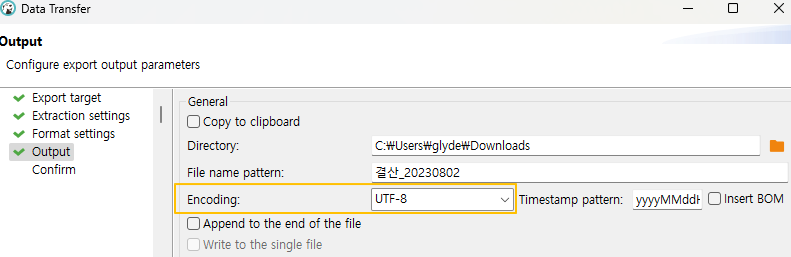
데이터 추출시 Encoding 타입을 선택하게 되는데, 대부분 UTF 형식으로 진행 하면서 문제가 시작됩니다
UTF 는 내부적으로 2가지 모드가 존재 합니다
-Big-Endian UTF-16 (BE)
-Little-Endian UTF-16 (LE)
(이 내용은 다른 페이지에서 다루겠습니다)
이 것을 구분하기 위해 화일 맨앞에 코드를 추가하게 되는데
이 것을 "BOM" (Byte Order Mark)이라고 합니다
'Hex Viewer' 등의 tool 로 화일을 열면 BOM 정보 확인 가능합니다
문제는
윈도우의 경우, 기본적으로 BOM 포함된 것을 가정하여 인식/처리 되는 것입니다. 엑셀도 마찮가지 입니다
그러나 아래 캡쳐처럼, DBeaver 데이터 추출시 "insert BOM" 이 default "N" 입니다
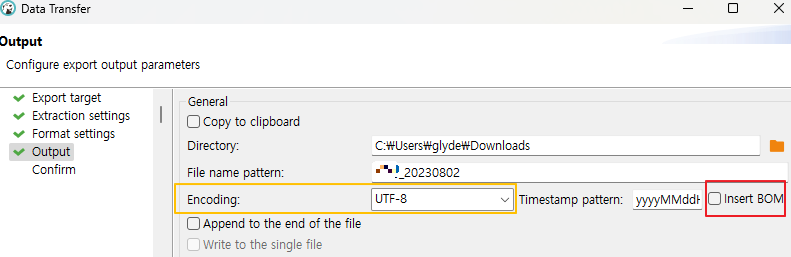
이 차이 때문에 엑셀에서 BOM 없는 UTF 화일을 열면서 한글 깨짐 현상이 발생합니다
(해결)
1. DBeaver 데이터 추출시 "insert BOM" 의 check box 를 체크 합니다
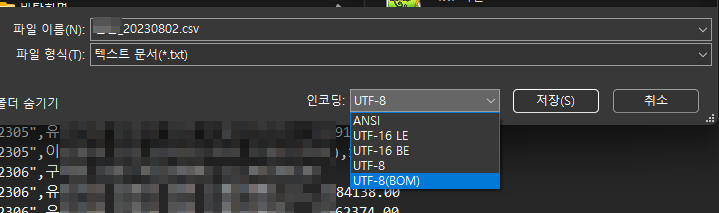
2. 이미 추출된 데이터라면, 한글이 정상 조회 되는 메모장에서 다른 이름 저장시,
인코딩 타입에 BOM 을 선택하여 저장 후 사용합니다
(추가)
"insert BOM" 기능은 DBeaver version 21.0.2 이후 포함되었습니다

'IT Tip' 카테고리의 다른 글
| [GPT] bard(시험버전) 출시와 gpt 비교 (0) | 2023.05.12 |
|---|---|
| Redmine 로그인 없이 사용 (0) | 2023.04.25 |
| [GPT] openai, ChatGPT 의 "Free Plan" 과 "Plus" 차이 (0) | 2023.02.20 |
| [GPT] gpt api 이용한 감성 분석 자동화-Google spreadsheet (0) | 2023.02.10 |
| [IT용어]MAU, DAU, MCU, ACU (0) | 2023.01.30 |